This article tries to summarize the more complete design doc and presents current state of the “Asset Project” in Blender.
Core Concepts
The main idea of current work is to keep Blender’s library system and build asset management over it, using “Asset Engines”, which will be python add-ons communicating with Blender through an “AE API”, in a similar way to our “Render Engine API” used e.g. by Cycles, POVRay, and other external renderers.
To simplify, those asset engines are here to provide to Blender lists of available items (they also include filtering & sorting), and ensure relevant .blend files are available for Blender at append/link time (or when opening a file). More advanced/complex pre- and post-processing may be executed through optional callbacks.
This allows us to not define “what is an asset” in Blender – Blender only knows about datablocks. Assets are defined by the engines themselves. The only addition to current Blender’s data model is a way to keep track of assets, variants and revisions (through UUIDs).
Work Landed in Master
A first rather big task has been to enhance filebrowser code and make it ready (i.e. generic enough) for assets listing. Final stages have been merged in master for Blender 2.76 – main immediate benefits include the ability to list content of several directories and/or .blend files at once, the ability to append/link several datablocks at once, a much quicker generation of thumbnails (when enabled), and a globally reduced memory footprint (especially when listing directories whit huge number of entries and enabling thumbnails).
Previews were also added to some more datablocks (objects, groups, scenes), and behavior of materials/textures previews generation was fixed.
Work Done in Branches and TODO’s
Fixing Missing-libs Issue
Currently, if you open a .blend file linking some data from a missing library, that linked data is totally lost (unless you do not save the main file). Work has been done to rather add placeholders datablocks when the real one cannot be linked from a library for some reason. This allows to keep editing the main .blend, and either fix the library path in the Outliner or make missing lib files available again at expected location, save and reload main .blend file, and get expected linked data again.
In addition, to remove the needed ‘save & reload file’ step, work is in progress to allow hot-replacing of a data block by another in Blender, this should allow to just fix broken lib path and automatically reload missing data.
Asset Engine Experiment – Amber
Amber is the experimental asset engine developed in parallel with the AE API. It also aims at being a simple, file-system based engine distributed as an add-on with Blender, once asset engine work is ready to be released!
It is based on file system storage with a JSON file to define assets & meta-data (like tags, descriptions, …).
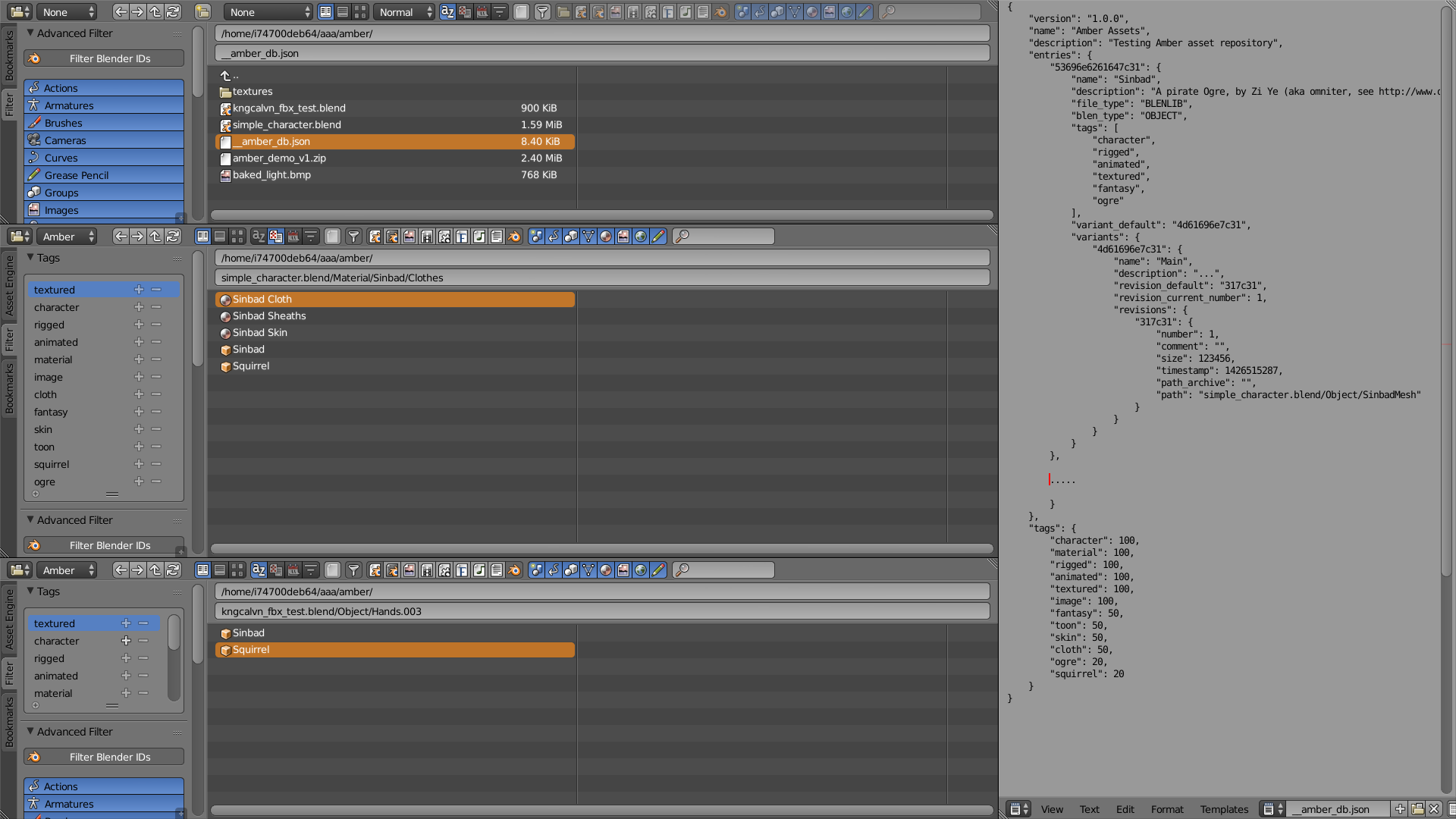
Amber at work!
Currently the basic browsing/importing part is up and running – in the picture above you can see three file browsers and a text block:
- The first browser (a “normal” one) shows the content of the test-case Amber repository (you’ll note the `__amber_db.json` file which defines an Amber repository).
- The second browser (an “Amber” one) shows that same directory as reported by our asset engine.
- The third browser (an “Amber” one too) shows the “filtering by tags” of Amber in action (the “character” tag is inclusive-selected).
- The text block shows an excerpt of the `__amber_db.json` content, with the definition of one asset and the definition of tags.
You can find that test-repo in that archive.
There are quite a few topics to be implemented yet to consider this work to be (even barely) usable, mostly:
- Add the “reload” ability (which also depends on the “missing-libs” work actually), such that Blender can query asset engines for updates (on file load or from user request).
- Currently you have to generate that JSON file by hand, which isn’t terribly fun. This will be addressed once the loading/reloading part is reasonably finished, though.
Conclusion (For Now)
Foundations of the future asset handling are mostly defined (if not coded) now, though we still have much work ahead before having anything really usable in production. Once again, this is a very condensed summarizing, please see the design task (and all sub-tasks and branches linked from there) for more in-depth and technical doc and discussions. And please do build and test the branches if you want to play with what’s already done – the earlier the testing and feedback, the better the final release!
This is something we have an immediate need for on our “Lunatics!” Project, so I’m very excited to see this being done! I’ve been trying out the daily build that already includes the Library recovery feature. Might have some feedback soon as most things seem to work as expected, but a few cases don’t seem to work — I need to do more testing to be sure I know what’s going on there.
Documenting procedures for library recovery is my first goal. We’ve lost too much time to recovering from these events and the resulting manual merges that have to be done.
The AE API approach is terrific, as it means we might be able to write adaptation code for our existing DAMS/VCS system, which is a secondary goal. I’m trying to find enough info to do that. I’m also working out the use cases we need to consider (link/append semantics, merging revisions on a file, maintaining render settings, etc).
I’d be glad to help with testing and documentation, if I can get to the point where I understand it myself.
For sure all feedback and testing is most welcome! AE branch is not ready for that though, still have to finalize the ‘id-remap’ work first (which allows live reloading of libraries, among other things) – and this is not simple, given how deep it dives into Blender roots. ;)
I hope to have id-remap ready for some testbuilds in coming weeks.
After some testing — the specific breakage that I still have is that it is not possible to correct an incorrect (that is, no longer correct) object name for a Proxy object.
Of course, this has never been possible, but it seems like it ought to be.
Blender is generally very forgiving about renaming objects. Normally, if you decide you should change the name of “Cube.064” to something mnemonic, like “DiningTable”, you don’t have to worry about doing that up-front — you can fix it any time you like.
But once you use the link / proxy feature to identify a character armature, that armature’s name had better not change. That’s inconsistent with expectations set up by other parts of Blender. At the very least, there should be a way to fix this by editing. But I have not yet found a way to do it. Maybe it can be done in Python with ‘bpy’. Not sure.
I tried this with the development build of 2.76 that has the new link behavior, but couldn’t find any way to select and alter the name.
Maybe this seems pretty minor. It’s a very specific use case, although a frequently-used one (I suppose that linking characters is one of the most common uses of Blender’s link system?).
This is exciting work Bastien! I’m not sure how much it falls under this project, but I’m looking forward to a more robust and predictable way of using linked assets with cloth and physics. I’ve found some workarounds but pretty tricky at the moment. Thanks again,
Thanks! Think this is more a physics area topic, though things like caching (alembic…) are not totally unrelated to asset management.
Do you plan to highlight placeholder or broken links somehow?
I guess it would be helpful to be able to easily identify them in both, the 3D View + Outliner.
Yeah, this is already done in Outliner in missing-libs branch actually (broken lib icon is even in master, though not used there ;) ). 3DView well, not sure… Right now placeholders for missing objects are just mere empties, we could add a special drawing type for those, but kinda think it’s not really worth it…
the addon looks a lot like reference desk, which already uses a json file and stuffs it with some data (not by hand)
Perhaps I could help with the coding?
Hey Bassam, sure, would be nice (though still too early for that right now, imho). Do you have some references for that work (like code, or at least website)?
When the linked geometry, materials, animation, etc were already hashed, you can just use their hashed value.
hashing of geometries are probably a bit slow but I think you can just use to assign random value as each editing geometry hash (or, to put it better, internal revision id).
external file references are another problem but you can use hashed asset path.
I have no idea of hash conflict though. but “git” uses hash-based and it-like way so it should not matter.
No, git is not a good example at all here, it does not divides a project in many sub-parts of different types which get interconnected in very complex ways. Not saying it’s totally impossible in absolute, saying you would have to design your whole file writing/reading with that concept at its core, which is not really an option for Blender currently.
I mean that git uses the SHA-1 hash of file-hash list as tree (directory) id.
https://git-scm.com/book/en/v2/Git-Internals-Git-Objects
IIRC nested hashes cause more collisions.
on the other hand, gettext uses collision-resistant hashing. so I just mentioned.
> not really an option for Blender currently.
ok, thanks.
I’ll move to publish-based workflow at some point.
oops, s/collision-resistant/collision avoidance/
big thanks for new asset management. I currently use new file browser for personal research.
however, on my non-organized files, it lacks these:
– “don’t show duplicates” option. saving as new file always causes duplicates.
– “private”/”public” built-in tag like Access modifiers of programming languages. many unuseful stuff should be hidden by default.
– license management for CC-BY-licensed assets, non-assets of research-purpose and suchlike. currently license management is troublesome.
> “don’t show duplicates” option. saving as new file always causes duplicates.
Must say I do not quite understand that sentence. ;)
Otherwise, private/public and license are all concepts that should be handled by asset engine imho, really want to keep blender’s side of this project as minimal and universal as possible. Good point though, we may need to add a way to reduce the number of datablocks shown to user by default (either by a simple ‘hidden’ flag, or maybe a more flexible ‘priority levels’ system, user could then chose how much of the ‘dirty internals’ of his assets he want to see in Outliner…
>Must say I do not quite understand that sentence. ?
well, my .blend files were pretty dirty because they are just for educating and testing ideas.
e.g. test_*_orig.blend, test_*_a.blend and test_*_b.blend have many duplicates.
hash comparison in listing and hash pre-calculation by its values and dereferenced object values should be able to prevent to show duplicates, I think.
In the other side, perhaps I should use publish-based workflow for even research purpose.
>blender’s side of this project as minimal and universal as possible
my problems are on file-based workflow.
auther and license tag should be useful for web asset sharing such like blendswap or google drive.
I don’t care that they are implemented in blender itself or default asset engine though.
Would really avoid hashing here, would make the overall browsing process much slower (unless we store pre-computed hashes, but even then…). Furthermore, dependencies between datablocks would likely break (or make it really hard to get working correctly) the hash idea (do you only define an object by its transform? same object with same transform but totally different geometry would hash the same, unless you also hash the linked geometry, materials, animation… aaaaaaarrrrrgggggg).
That makes sense if you’ve got like, character_V01.blend, character_V02.blend ect… in the same directory, how can you display only the last ?
Maybe there is some way to filter , maybe with some python magic ?
That would be asset engines’ responsibility to present those as revisions to Blender…
Hi Bastien,
Nice work and comprehensive post. I think it’s a really important part of Blender and it’s great you tackle it! Ton asked for some comments/suggestion. Maybe some of those ideas are already doable, but if, it means it could be made easier/more visible to user:
– It would be great to have a way to make the linking system only load the preview image now that we have it (with a image empty, which already is in Blender for years), but load the full mesh/object/group/whatever for Render. It would make opening files with lots of heavy libs fast, resilient (if the file is not available for some reason, the preview is still there, packed in the opened blend because it just takes some KB), and it would make the rendering in Blender’s UI use almost the same memory amount as the command line render.
– It would be great to contact the Blendswap guys to implement a first version we could directly beta-test, to get a filling and more enthusiasm (nobody or few people will implement an engine and create a big library only for test purpose). With for example file type (material, rig, model, etc…), license type, author, render engine and such tags to use the filtering options, the network/authentication possibilities, etc… Blendswap already has many of those tags and a big user-base, so it will make testing and further design much better and more fun.
Just my 2 cents :) You already did a great job.
Thanks :)
I) Though I can see the reason, I do not think this would be really doable (well, it’s kind of partially done by the ‘placeholder’ ID concept, but…). Thing is, this would only concern objects, and it could make linked objects’ dependencies (geometry, material, etc.) rather hairy. Think if one really wants/needs such feature, it should rather go through an addon which would replace some datablocks by others (lither ones) after loading, and use pre-render hook to replace them again by ‘real’ version for rendering. There is also the concept of ‘variants’ in our asset project that could be used for such means as well. But again, would not add that at the core of our libdata handling, it’s already complicated enough code. ;)
II) Yep, that’s good idea to try to involve some online repo here – but this is yet too early currently, would rather have some reasonably finalized version of the API first.
Are you planning to get rid of fake user concept (replace it with assets?)?
No, that really not the same topic imho… Fake user is about keeping some unused data in a .blend file, it’s totally orthogonal to asset project, which is rather how to access and manage collections of reusable datablocks.
Thats almost perfect – we already use an asset manager at 3Dami (3dami.org) that saves out .json files containing all of the meta information – it will be almost no work to get it compatible with Amber. Linking problems are our biggest issue at 3Dami, and it looks like this will solve all of them:-)
The ability to have an amber library pre-configured to be automatically used, plus an open file dialog that lets you open files to edit assets from said library (with a button from the splash screen) and it will be perfect:-)
In order to prevent spam, comments are closed 15 days after the post is published. Feel free to continue the conversation on the forums.